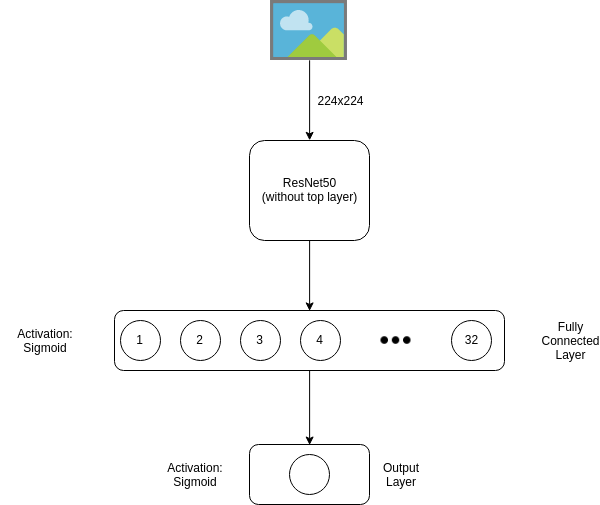
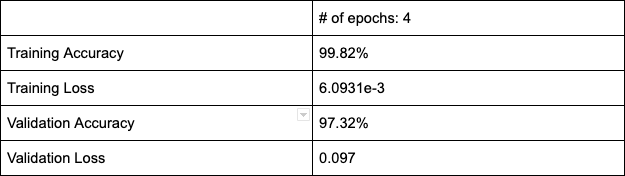
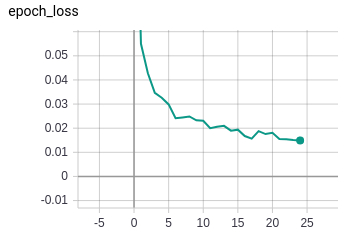
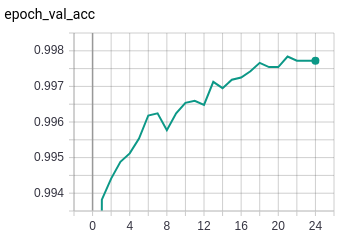
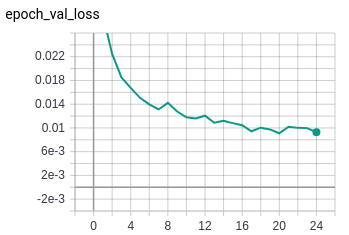
There are over 80 ways of draping a saree. These are mostly styles based on the region. And with the region come the designs and the material. So, the permutations and combinations that one has to go through to choose “one perfect saree” are numerous. So, we set out to understand ‘What Women Want’ while choosing a saree. This was to better understand the social, economical and cultural perceptions towards the saree today and to attempt a solution using new technologies like AI & Vision computing to make the experience of buying that “One perfect saree” memorable, social and hassle-free.
Sarees are one of the oldest clothing articles on the face of the earth. It pre-dates most of the clothing cultures we now have. This traces back to around 2000 – 1800 bc (https://en.wikipedia.org/wiki/Sari). Sarees have not just lasted so long but have also modernized in trends and design with time. Even the manufacturing and the sale of sarees has gotten more sophisticated over time. So, you might think choosing a saree should be just as simple as choosing a shirt/trouser. It’s just not that simple.
Understanding Who Wear Sarees Today
The NY times, claims saree draping to be a nationalist agenda (https://www.nytimes.com/2017/11/12/fashion/india-nationalism-sari.html) but as stated before, saree draping predates all of this. So, we decided to take the subcontinent into consideration, on multiple factors and with information from surveys and trends our findings on who wears sarees can be seen as below:
- Religion divide
A survey by the NSSO states that saree is not just a hindu attire but christians and muslim households spend considerable share of women’s clothing budget on sarees
- Economic divide
Saree breaches the class divide. The effluent class’s saree buying is at 77% which is only slightly higher than the bottom class’s 72%.
Understanding What Women Look For In A Saree
From our earlier understanding that most southern states in the subcontinent favor sarees than the northern ones, we conducted a survey with a small sample size of women, Majorly from tier 2 and tier 3 towns to understand what do they look for in a saree.

who is interested in sarees
In the towns, it’s a growing trend that the majority of women in their 20’s are preferring to move to the cities for work and education. The women above 50’s in the towns are parents to the children who are moving to the cities. So, Majority of sarees are being purchased by women who are over 40 years old.

what design are they looking for
The graph states that the majority of people looking to buy a saree are always looking for thread works on their sarees. This could be because it is easier to maintain than stones and is not as simple as checks and prints. The prints fall second but lag by a fair margin.

Is Design Everything
In every other branding that we see for sarees, we see all the bells and whistles. The shiny rocks on the saree, the glossy silk, the simple prints, but what are people actually looking for?
Designs of the saree seem to be the least important when it comes to preferences, The feel, the material and the quality are what are looked for. In other terms, longevity and usability of the sarees are important than the design. Also, 80% of women choosing design fall between 20-35 years.
Apart from the above insights we have also discovered the following:
- Gifting a saree is very common in india
- Majority of women buying sarees buy it for everyday usage and the purchase of fancy sarees is for special occasions where all the classes tend to spend more than usual for that one saree.
So, now that we know what women look for in a saree, Lets look at their buying behavior.
Understanding How They Shop For Sarees

A process of buying starts in the minds of the consumer, which leads to the finding of alternatives between products that can be acquired with their relative advantages and disadvantages. From earlier, we know that the quality factor prevails in the first position, color and design, comfort and style and price are securing successive ranks respectively.
From more surveys and interviews, we understand the general shopping patterns.

The graph here shows how the market has been growing with larger name brands across all the classes scaling ethnic wear in india. This also shows how affordable ethnic brands are in comparison to western wear.
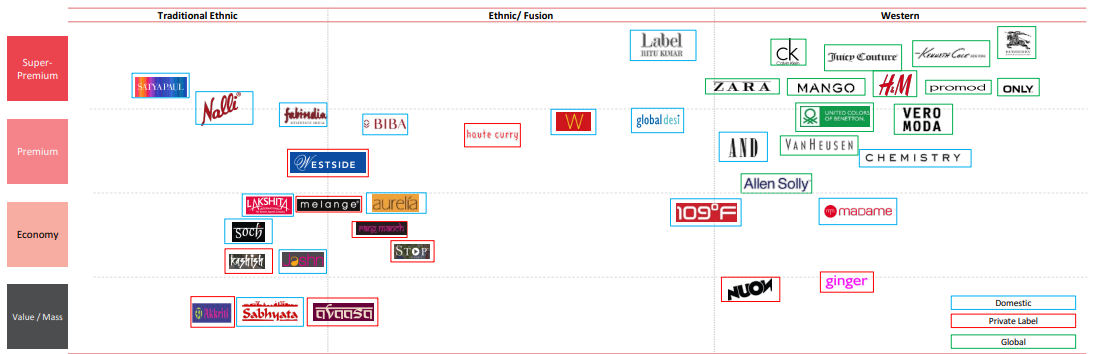
The saree market in india is one of the largest apparel market in the country. There is a significant shift away from traditional sarees towards ethnic wear and western wear. Though the growth seems to be slower for sarees, it still would be the market leader in time to come.
The Influencers
- Increasing number of occasions
With the growing social boundaries, the number of occasions have increased in india. Formal, informal and traditional occasions have made women increase their wardrobe.
- Impulsive buying
With offers everywhere and the technology being present in your palm, attraction towards any commodity has fueled impulsive buying for the average indian.
- Influence of media
Soaps, Movies, Ads, Social media, Personal messages. The visual format of content sharing is enabling users with millions of options and is contributing towards this change in behaviour
- Increase in fashion sense
With the evolving fashion and media, people are not just looking for utility but for aesthetics too. And with larger brands spreading across the country with scale production, aesthetic clothing is affordable to everyone
- Aspirational buying
Women today are empowered with the ability of higher spending. Along with it, good clothing is aspirational too. A memorable occasion needs aspirational clothing to complete it.
Where Do They Buy Sarees From
From sales of sarees by local vendors on instagram, facebook marketplace and amazon and flipkart to larger chains and stores, Women today are shopping for sarees in every vertical available. The online market is one amongst the most important reasons in the growth of sarees in India. Since the adoption of Sarees is majorly in rural areas where penetration on internet is increasing day by day, this may result in opening of a brand new revenue pockets for stockholders in Indian sari business The increasing penetration of

While the online market and popup stores mostly takes care of the impulse buying and everyday needs of sarees, when it comes to shopping for occasions and events; women still prefer buying sarees in larger stores or from reputed brands. They dont mind the extra effort (and/or) the overhead cost that retail stores bear.
Internet, the increasing buying power of women, high brand consciousness and fashion sense has made e-commerce a crucial medium of shopping.
Customer saree shopping journey
From the customer’s shoes, Buying a saree is a very deeply embedded process with numerous points of friction and points of leverage. Customers interaction with the shopkeeper is only a part of a larger journey that they’re on.

The above mentioned is just an outlier of the shopping experience. The nuances and the conditions they evaluate change with every customer.
Conclusion: (This Is) What Women Want.
- Quality and assurance of the commodity plays a major factor on the buying
- Emotionally, validation and feedback on what they wear plays a great role in the choice that women make while buying a product
- Validation and feedback on a product are observed to be attained through conversation on the look and feel and the costing of a saree
- Though buying a saree requires the evaluation of quality and feel, women prefer the design, work and other visual elements to look at a saree
- Brand names play a major role
- The idea behind fashionable clothing is to make someone look beautiful so the search is always for a saree that one looks beautiful in